Why on-device agentic AI can't keep up
There's a growing narrative that on-device AI is about to free us from the cloud - the pitch is compelling. Local inference means privacy, zero latency, no API costs. Run your own agents on your computer or phone, no cloud required.
Indeed, the pace of improvements in open weights models has been spectacular - if you've got (tens of) thousands to drop on a Mac Studio cluster or a high end GPU setup, local models are genuinely useful. But for the other 99% of devices people actually carry around, every time I open llama.cpp to do some local on device work, it feels - if anything - like progress is going backwards relative to what I can do with frontier models.
There are some hard physical limits to what consumer hardware can do - and they're not going away any time soon.
For the purposes of this article, I'm referring to agentic capabilities in a personal admin capacity. Think searching emails and composing a reply and sending a calendar invite. More advanced capabilities like we see in software engineering are even harder to do on device.
The state of RAM
While the models themselves are getting hugely more capable, there's an intrinsic problem that they require a lot of ideally fast RAM.
Right now, 16GB laptops are the most common configuration for new devices - but 8GB is still very common.
On phones, the situation is (understandably) even more constrained. Apple is still shipping phones with 8GB for the most part - the iPhone 16e and 17 ship with 8GB of RAM, and only the Pro models have 12GB. Google on their Pixel lineup is more generous, shipping 12GB on the 'standard' models, with 16GB on the Pro models.
The issue is that this RAM isn't just for on device AI models. It's also for the OS, running apps. Realistically you want at least 4GB for this - and that's cutting it fine for web browsers and other RAM heavy apps on your phone. On laptops I'd suggest you want at least 8GB of RAM for your OS and apps.
This leaves very little space for the AI capabilities themselves - perhaps 4GB on non-"Pro" models and 8GB on the Pro models. Equally even a new MacBook Air is only going to have 8GB of space in RAM for AI. And these are brand new devices. The majority of people are running multiyear old hardware.
KV cache eats everything
The models present one space issue. A 3B param model (which in comparison to frontier models is tiny) requires on the order of 2GB in a highly quantised (think compressed) variant. A 7B param model - which in my experience is vastly more capable - requires more like 5GB. In comparison, full scale models are around the 1TB mark - 200-500x larger.
While this is an incredible achievement to get any level of "intelligence" in such a (relatively) small space, you can see the issue already - a 7B model won't fit in most new consumer hardware, leaving only space for a 3B model.
This is only half of the problem though. You don't just need RAM for storing the model, you also need space to cache the context of the interactions with the models. This is where it quickly becomes unusable for many agentic use cases.
You can get away with a very small amount of context for simple tasks - think text summarisation or tagging. This may fit into a few thousand tokens of KV cache, and is doable on device (both Apple and Google limit on device context to 4K tokens from my research on phones).
Even 'basic' agentic tasks quickly become unusable at this 4K limit though.
Tool definitions (think 'send message', or 'read calendar events') alone probably require that size of context. That's before you start doing prompts against it, or including data from your phone (the actual iMessages, or your emails).
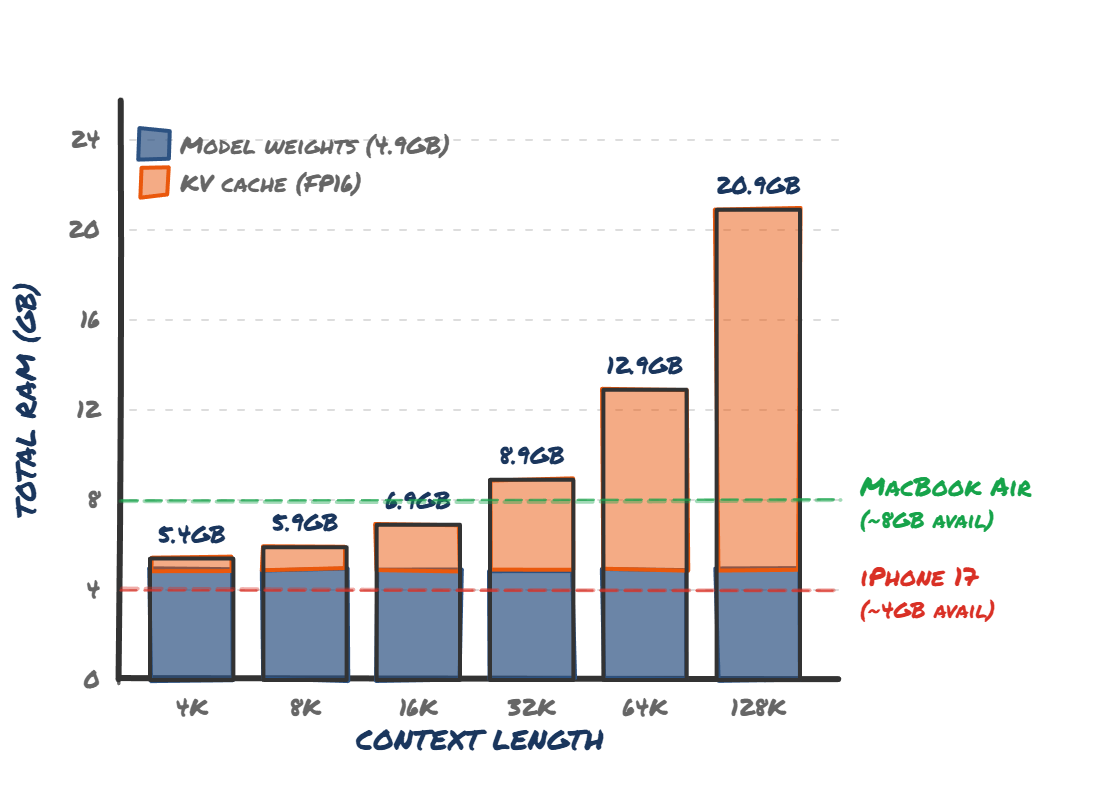
KV cache memory for a 7B Q4 model at different context lengths. Even at 32K context, you've blown past what an iPhone 17 can offer.
It simply doesn't work in 4GB, or even 8GB. At a bare minimum I think you'd want 32K tokens of context window, and ideally a 7B+ param model. This is getting close to 16GB of RAM[1] just for the AI part of your device. As such, we need to see consumer devices with 24GB, or ideally 32GB of on device memory before a lot more possibilities open up.
There are techniques that help close the memory gap - grouped-query attention, sliding window attention, quantised KV caches. They're real and they're shipping. But they often trade off precision in exactly the scenarios agentic workflows need most - multi-hop reasoning, precise tool calling, and maintaining coherence across longer conversations. They help, but not nearly enough.
But then the supply chain issues started
Arguably we were on track to hit this - 32GB laptops were becoming more common. But then the price of RAM skyrocketed over 300%. Manufacturers are more likely to cut RAM now than add more. And given the huge lead time of additional DRAM manufacturing capacity, this situation is unlikely to change in the near future.
This is a great example of crowding out. HBM (datacentre class RAM) and standard DDR5 compete for the same DRAM wafer starts - so every wafer allocated to HBM for datacentres is one not used for the DDR5 in your laptop.
However, speed is an issue
Let's run the hypothetical that overnight we have far more DRAM manufacturing capacity across the globe. There's still another massive issue - speed.
While devices have impressively fast compute available to them, especially in something that you can carry around with you in your pocket, there's another context related problem that pops up.
A consumer device might be able to process tokens on the order of 30tok/s on a small, local model. This is actually surprisingly usable - not fast, but probably passable for many use cases.
However, as context scales - and as I described before, it massively scales in agentic tasks - the processing speed drops off a cliff. To put this in perspective, even a Radeon 9070 XT - a 304W desktop GPU - drops from 100 tok/s to less than 10 tok/s on an 8B model at 16K context once you factor in prefill. Good luck getting that on a phone.
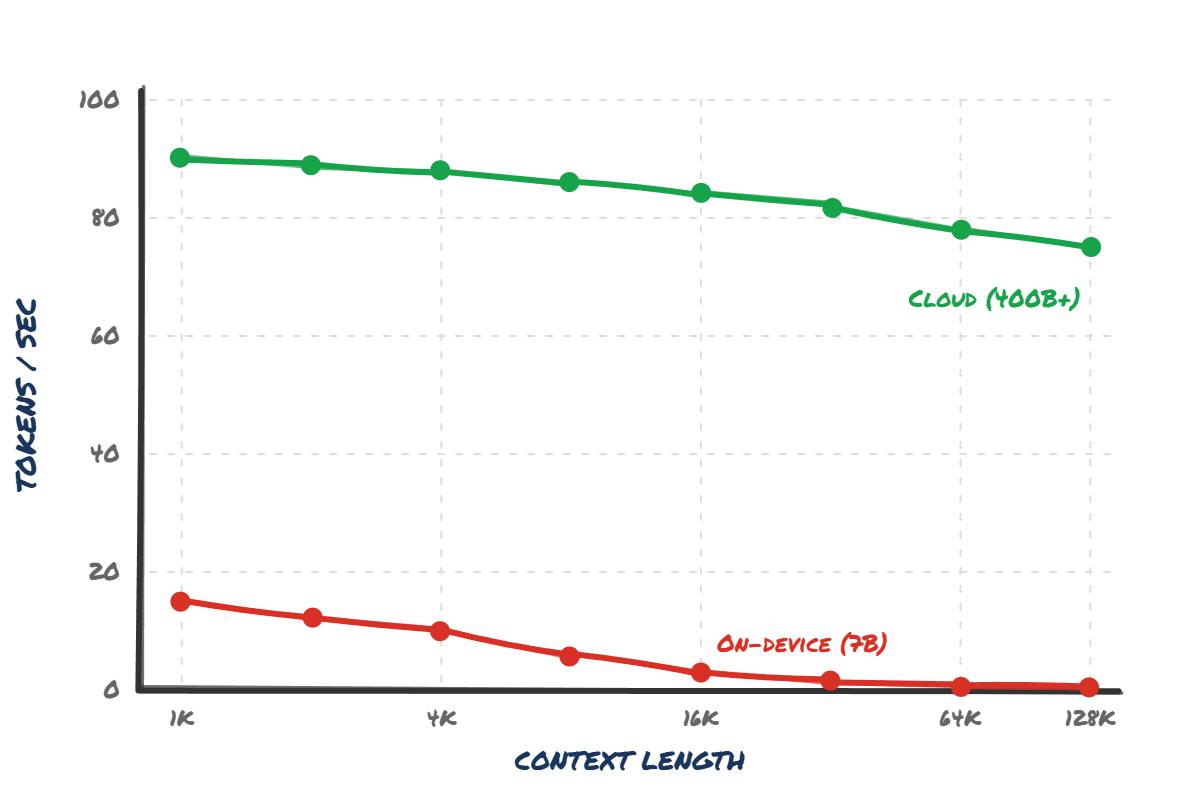
Cloud inference barely flinches as context grows. On-device collapses to near zero past 16K tokens - exactly where agentic tasks start.
Speculative decoding - where a tiny draft model proposes tokens and a larger model verifies them - can help with speed. But it requires holding two models in RAM simultaneously, which makes the already dire memory situation even worse.
At this speed even a quick couple of paragraphs long email might take a minute to generate - at which point it's almost certainly quicker to type it yourself.
Even worse, hammering your phones hardware this hard for extended periods of time really impacts battery life and makes your phone heat up, so much so that the phone has to slow itself down to avoid overheating. This makes it even slower.
This is a far more difficult challenge than just providing more RAM. You need more compute (for prefill) and much faster memory. These are both expensive (with or without supply chain issues) and much more power hungry. It feels like we are still a way off even GDDR memory - which itself is still ~an order of magnitude slower than datacentre class HBM - being able to be put into a phone.
As you can see, between the RAM limits and speed limitations, on device models are going to have a very difficult time in the next year or two getting any real traction for even basic agentic workflows. Of course there could be some architecture breakthroughs that allow this - but assuming that doesn't happen - I think it is safe to say that most of us will be running most of our tokens through a cloud provider for the foreseeable future.
Cloud offload
This brings me to one last point - compute capacity on the cloud itself. While Apple has pushed the narrative of on device for simple tasks, and offloading to more capable models on the cloud, running the maths on this actually exposes some serious issues for agentic tasks.
It's hard to fathom the scale of the iOS installed base (and Android even larger). There's somewhere on the order of 2 billion active iOS devices, and another 4 billion Android devices out there.
The compute demands to bring this even on the cloud to even a sizeable minority of these users is enormous. I estimate that Claude Code has low single digit millions of users, and I strongly suspect it is melting Anthropic's entire compute supply.
If Apple were to roll out agentic capabilities in to the OS - even with a lot of limitations - you are easily looking at requiring an entire Anthropic in terms of compute capacity, for just a small minority of iOS users.[2]
If anyone tells you on device models are just round the corner, they clearly haven't run the maths on the memory and compute requirements. Datacentres aren't going anywhere soon.
This is a giant simplification and there are many approaches to reduce this. For example, hybrid attention significantly reduces KV cache memory requirements, but does trade off precision. There's a great roundup by Sebastian Raschka, but it gets extremely technical very quickly. ↩︎
Assuming even a 5% rollout to 100M active iOS users, and each user uses 5% of the tokens of a Claude Code user. This feels ~roughly reasonable in terms of token consumption - but it really depends on what the product looks like. Directionally this feels right to me though. ↩︎