What's going on with Gemini?
Google is in a strange spot right now. They've got arguably the deepest research bench in the industry, their own custom silicon, and effectively unlimited money - and yet most developers I talk to barely touch Gemini day-to-day. The recent Google I/O announcements crystallised a lot of what I find confusing about their AI strategy, so I wanted to write down where I think they actually stand.
The state of play
The consensus seems to be that currently Anthropic and OpenAI are very much in the lead for frontier model intelligence, with each of those two labs trading blows every month. This may change in the near future - if Anthropic releases Mythos-class models that OpenAI doesn't have an answer to - but right now I think most practitioners would agree that GPT5.5 and Opus 4.8 are roughly in the same ballpark.
After that, you have Google, with Gemini 3.1 Pro being in benchmarks ahead of the Chinese models but behind the flagship Anthropic/OpenAI models. In my personal experience though I've had better results from the best-in-class Chinese models (GLM 5.1 and Qwen 3.7) than Gemini 3.1 Pro at software engineering tasks.
Gemini 3.5 Flash is confusing
The main model announcement at Google I/O was Gemini 3.5 Flash. The benchmarks of it were underwhelming at coding:
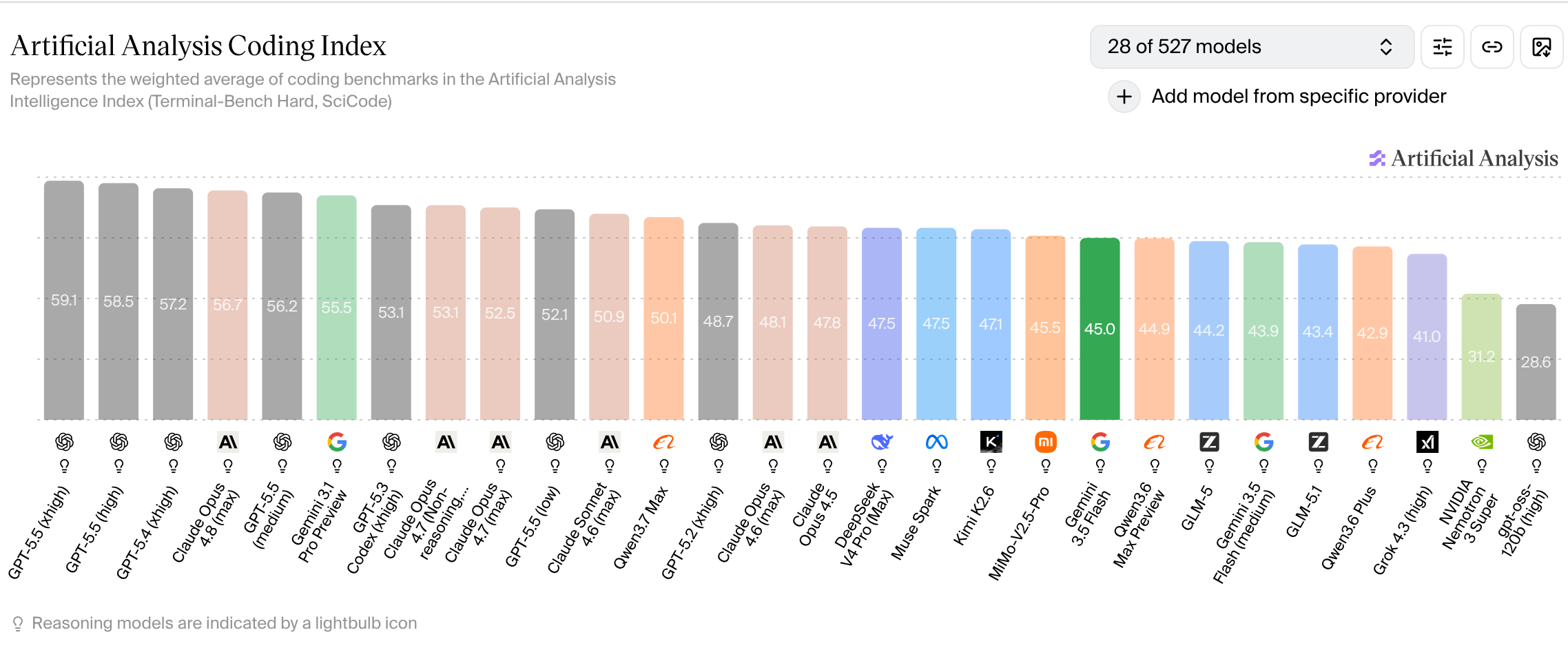
Gemini 3.5 Flash on the Artificial Analysis Coding Index - solidly mid-pack. Source: Artificial Analysis.
However, the model is super fast - roughly 4x faster in tokens per second than the aforementioned Anthropic/OpenAI models:
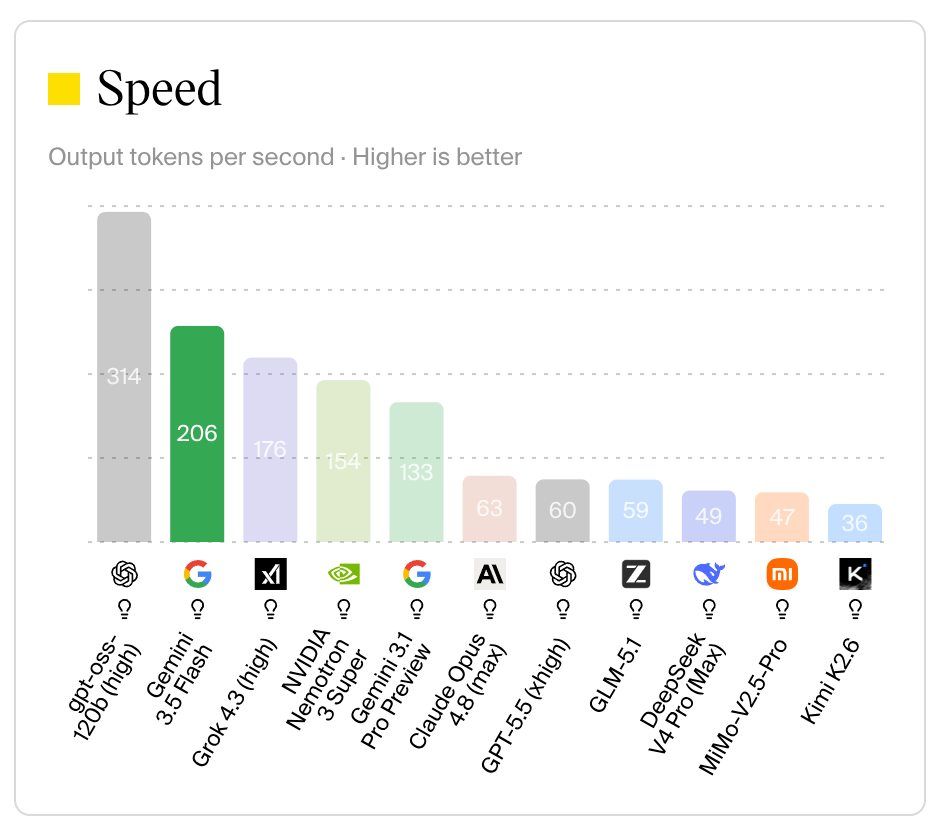
Output tokens per second - Gemini 3.5 Flash at 206 t/s, far ahead of Opus 4.8 and GPT-5.5. Source: Artificial Analysis.
This definitely is really interesting development, especially for user facing applications which can appear very sluggish to users.
But - the big but - is the huge price increase they announced - 3x more expensive than the previous flash release. At $9/MTok it is vastly more expensive than the best in class Chinese models, and I'm struggling to see where this fits - if you want best in class intelligence you pay the extra for Opus/GPT5.5, if you want cheap but not-as-clever the Chinese models fit the bill well. The risks around Chinese models are somewhat overplayed in my opinion - you can self-host a lot of them, or use US-based inference providers via OpenRouter.
Is this model really for Google itself?
Having said all that, perhaps really this model isn't designed for external use in the same way that the OpenAI/Anthropic models are. Clearly Google consumes an enormous amount of tokens internally - for all their products like AI mode, Gmail, etc.
If you look at it that way, the model makes far more sense. The speed of the model really matters for a lot of the Google use cases - AI mode is very user driven and Google knows better than anyone that speed really matters. And the actual serving cost Google pays is almost certainly a fraction of the external facing price, so that becomes irrelevant.
The most interesting part of this story though, is this excellent comment on Hacker News from someone that estimated the size of the model and the fact that it should run on one TPU 8i card (Google's latest custom inference hardware).
This does give Google a huge advantage. They are the only frontier lab that (currently) designs its own AI hardware. While other labs certainly optimise their models to the hardware, and also no doubt have a lot of say in driving the Nvidia/AMD roadmaps to their specifications, the model teams and hardware teams in Google almost certainly collaborate to a far greater level than the other labs.
This really matters. If you have a very good steer on upcoming hardware you know the right size of models to target training runs to aim for. And equally, research from Google Deepmind can go straight into the hardware roadmap without any negotiations. [1]
It'll be very interesting to see how this continues to develop. Inference efficiency will be the key driver to actual unit economics in AI, and Google may develop an outsized lead in this.
Coding agents
The one real weakness I think Google has though, is their confusing and incoherent strategy on coding agents. While Anthropic has Claude Code, and OpenAI has Codex, in true Google style they have ended up with a smorgasbord of tools.
There is currently Antigravity, Jules, Gemini Code Assist, Gemini CLI and AI Studio all doing slightly different things. This doesn't include some other agentic SWE tools they have for specialised purposes (like Android Studio).
They announced that Gemini CLI is being discontinued and folded into Antigravity, but I very rarely come across any developer using Google-based SWE tooling.
This is a huge issue for Google - there is no doubt that Claude Code and Codex is producing a lot of very detailed telemetry and training data that can be used to improve further models. Without this being resolved, Google does have an extreme weakness in the fastest growing - at least revenue-wise - segment of AI.
While I definitely wouldn't write Google off - they do have enormous structural advantages in other areas - I get the feeling that because Google has such a bespoke internal software development workflows[2] their isolation from what "the rest of the industry" does in software is so large it's perhaps hard for them to really reason about agentic tooling for the rest of the industry.
So, what's going on with Gemini?
My read is that Google is playing a genuinely different game to OpenAI and Anthropic. Gemini 3.5 Flash only looks strange if you assume it's meant to win the same race - priced and tuned for Google's own gigantic internal token consumption, with the TPU advantage baked in, it makes complete sense. Where they're actually behind is the developer-facing surface: a confused tangle of coding tools and an org that struggles to reason about how the rest of us build software. If Google sorts out the agent story, the structural advantages underneath - the silicon, the research, the integration - could make them very hard to beat. That's a big if. But I wouldn't bet against them.
While it's hard to say if there was any truth in this - or it was just a negotiation strategy - there were rumours of OpenAI being unhappy with direction/progress Nvidia was making earlier this year: https://finance.yahoo.com/news/sam-altman-pushes-back-report-213000823.html ↩︎
Google engineers have an enormous amount of home built/custom/internal tooling that is uncommon outside of Google-scale companies. They use different source control, build tooling, testing infrastructure and build deployment to the rest of the industry - for very good reasons! But this stack is absolutely overkill for 99% of companies, and when you are used to thinking about SWE at Google scale I suspect it is very difficult to reason how people build software outside of that ecosystem. ↩︎