What next for the compute crunch?
I thought it'd be a good time to continue on the same theme as my previous two articles The Coming AI Compute Crunch and Is the AI Compute Crunch Here? given that both OpenAI and Anthropic are now publicly agreeing they are (very?) compute starved.
Usage is absolutely exploding
I came across this really interesting tweet from the COO of GitHub which really underlines the scale of change that the world is seeing now:
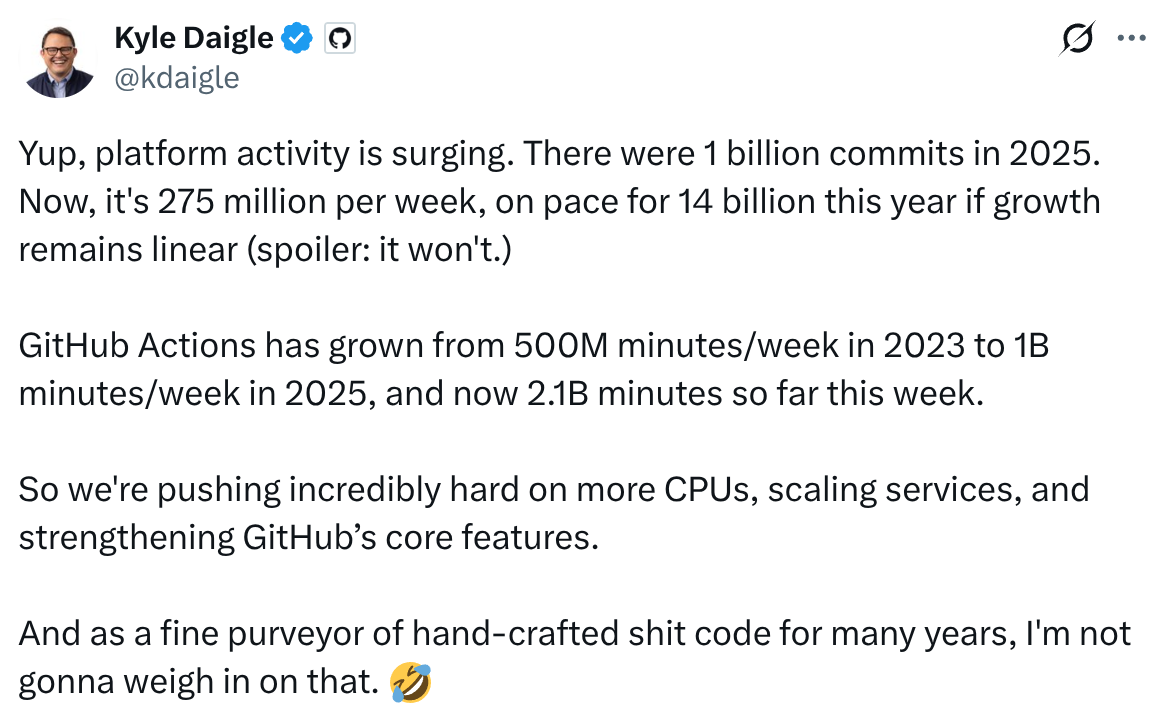
This shows that GitHub in the last 3 months (!) has seen a ~14x annualised increase in the number of commits. Commits are a crude proxy for inference demand - but even directionally, if we assume that most of the increase is due to coding agents hitting the mainstream, it points to an outrageously large increase in compute requirements for inference.
If anything, this is probably a huge undercount - many people new to "vibe coding" are unlikely to get their heads round Git(Hub) quickly - distributed source control is quite confusing to non engineers (and, at least for me, took longer than I'd like to admit to get totally fluent with it as an engineer).
Plus this doesn't include all the Cowork usage which is very unlikely to go anywhere near GitHub.
OpenAI's Thibault Sottiaux (head of the Codex team) also tweeted recently that AI companies are going through a phase of demand outstripping supply:
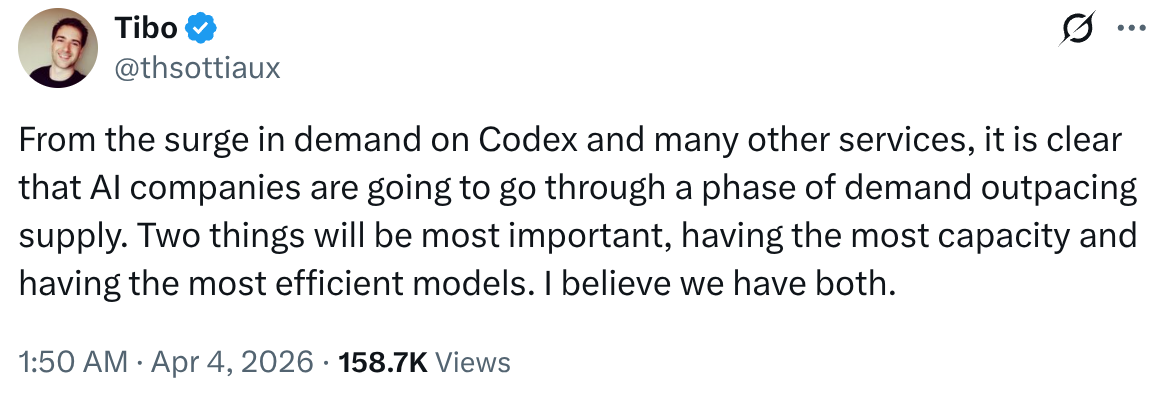
It's been rumoured - and indeed in my opinion highly likely given how compute intensive video generation is - that Sora was shut down to free up compute for other tasks.
All AI companies are feeling this intensely. Even worse, there is a domino effect with this - when Claude Code starts tightening usage limits or experiencing compute-related outages, people start switching to e.g. Codex or OpenCode, putting increased pressure on them.
What's actually going on?
As I mentioned in my last articles, I believe everyone was looking at these "crazy" compute deals that OpenAI, Anthropic, Microsoft etc were signing like they were going out of fashion back in ~2025 the wrong way.
Signing a $100bn "commitment" to buy a load of GPU capacity does not suddenly create said capacity. Concrete needs poured, power needs to be connected, natural gas turbines need to be ordered[1] and GPUs need to be fabricated, racked and networked. All of these products are in short supply, as is the labour required.
One of the key points I think worth highlighting that often gets overlooked is how difficult the rollout of GB200 (NVidia's latest chips) has been. Unlike previous generations of GPUs from NVidia the GB200-series is fully liquid cooled - not air cooled as before.
Liquid cooling at gigawatt scale just hasn't really been done in datacentres before. From what I've heard it's been unbelievably painful. Liquid cooling significantly increases the power density/m2, which makes the electrical engineering required harder - plus a real shortage of skilled labour[2] to plumb it all together - and even shortages of various high end plumbing components has led to most (all?) of the GB200 rollout being vastly behind schedule.
While no doubt these issues will get resolved - and the supply chains will gain experience and velocity in delivering liquid cooled parts - this has no doubt put even more pressure on what compute is available in the short to medium term.
Even worse, Stargate's 1GW under construction datacentre in the UAE is now a chess piece in the current geopolitical tensions in the recent US/Iran conflict, with the Iranian government putting out a video featuring the construction site.
The longer term issue I wrote about in my previous articles on this subject is the hard constraints on DRAM fabrication. While SK Hynix recently signed a $8bn deal for more EUV production equipment from ASML, it's unlikely to come online for another couple of years. Indeed I noticed Sundar Pichai specifically called out memory as a significant constraint on his recent appearance on the Stripe podcast.
While recent innovations like TurboQuant are extremely promising in driving memory requirements down via KV cache compression, given the pace at which AI usage is growing it at best buys a small window of breathing room.
What next?
I believe the next 18-24 months are going to be defined by compute shortages. When you have exponential demand increases and ~linear additions on the supply side, the market is going to be pretty volatile, to say the least.
The cracks are already showing. Anthropic's uptime is famously now at "1" nine reliability, and doesn't seem to be getting any better. I don't envy the pressure on SRE teams trying to scale these systems dramatically while deploying new models and efficiency strategies.
We've seen Anthropic introduce increasingly more heavy handed measures on the Claude subscription side - starting with "peak time" usage limits being cut significantly, and now moving to ban even claude -p usage from 3rd party agent harnesses - no doubt to try and reduce demand.
The issue is that if my guesswork at the start of the article is correct and Anthropic is seeing ~10x Q/Q inference demand there is only so much you can do by banning 3rd party use of the product - 1st party use will quickly eat that up.
And time based rationing - while extremely useful to smooth out the peaks and troughs - can only go so far. Eventually you incentivise it enough that you max out your compute 24/7. That's not to say there isn't a lot more they can (and will) do here, but when you are facing those kind of demand increases it doesn't end up getting you to a steady state.
That really only leaves one lever to pull - price. I was hesitant in my previous articles to suggest major price increases, as gaining marketshare is so important to everyone involved in this trillion dollar race, but if all AI providers are compute starved then I think the game theory involved changes.
The paradox of this though is that as models get better and better - and the rumours around the new "Spud" and "Mythos" models from OpenAI and Anthropic point that way - users get less price sensitive. While spending $200/month when ChatGPT first brought out their Pro subscription seemed almost comically expensive for the value you could get out of it, I class my $200/month Anthropic subscription as some of the best value going and would probably pay a lot more for it if I had to, even with current models.
We're in completely uncharted territory as far as I can tell. I've been doing a lot of reading about the initial electrification of Europe and North America recently in the late 1800s/early 1900s but the analogy quickly breaks down - the demand growth is so much steeper and the supply issues were far less concentrated.
So, we're about to find out what people will actually pay for intelligence on tap. My guess is a lot more than most expect - which is both extremely bullish for the industry and going to be extremely painful for users in the short term.[3]
Fundamentally, I believe there is a near infinite demand for machines approaching or surpassing human cognition, even if that capability is spread unevenly across domains. The supply will catch up eventually. But it's the "eventually" that's going to hurt.
Increasingly large AI datacentres are skipping grid connections (too slow to come online) and connecting straight to natural gas pipelines and installing their own gas turbines and generation sets ↩︎
I've also read that various manufacturing problems from NVidia has lead to parts leaking, which famously does not combine well with high voltage electrical systems. ↩︎
One flip side of this is how much better the small models have got. I'll be writing a lot more on this, but Gemma 4 26b-a4b running locally is hugely impressive for software engineering. It's not quite good enough, but perhaps we are only a few months off local models on consumer hardware being "good enough". Maybe it's worth buying that Mac or GPU you were thinking about as a hedge? ↩︎