What happens when coding agents stop feeling like dialup?
It's funny how quickly humans adjust to new technology. Only a few months ago Claude Code and other agents felt like magic, now it increasingly feels like browsing the internet in the late 90s on a dialup modem.
Firstly, Anthropic has been suffering from pretty terrible reliability problems . And looking at OpenRouter's data they are not alone (nb. OpenRouter's data is not conclusive, but I believe it does give a somewhat interesting overview of reliability).
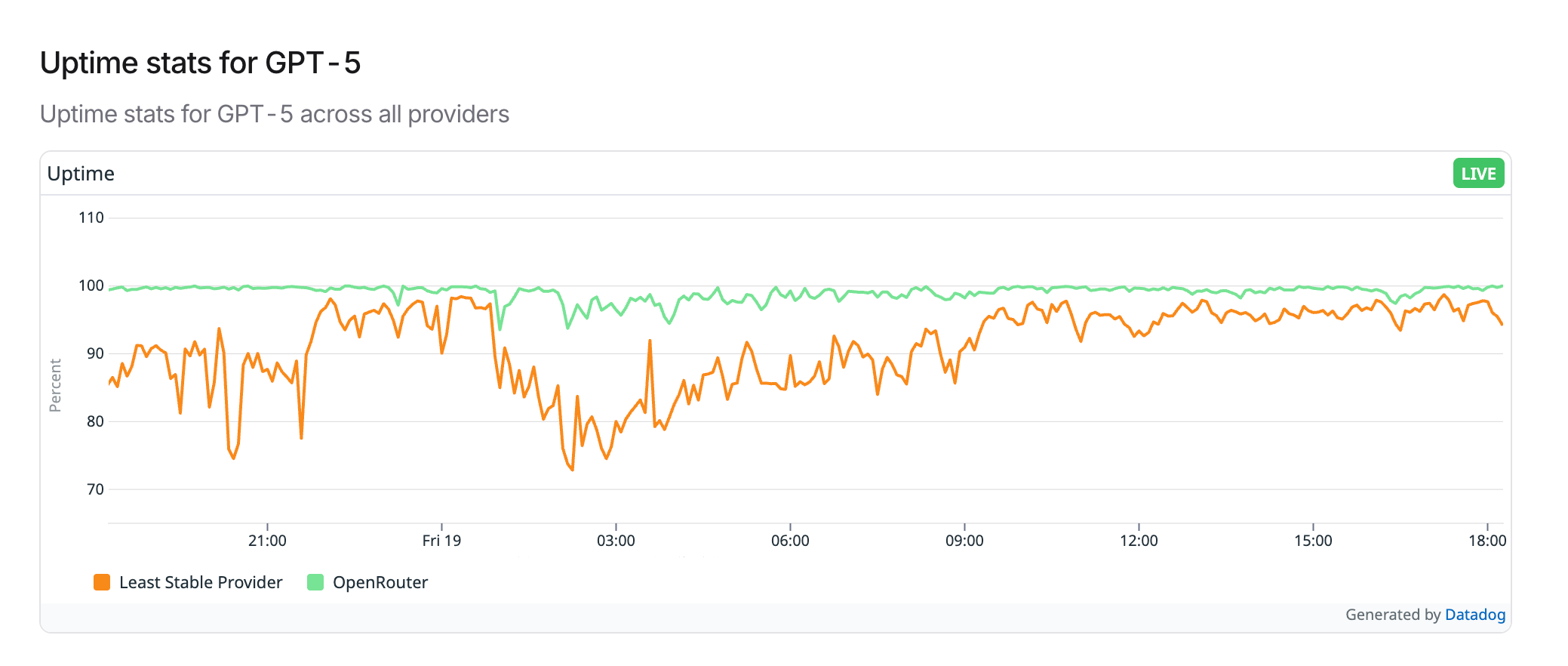
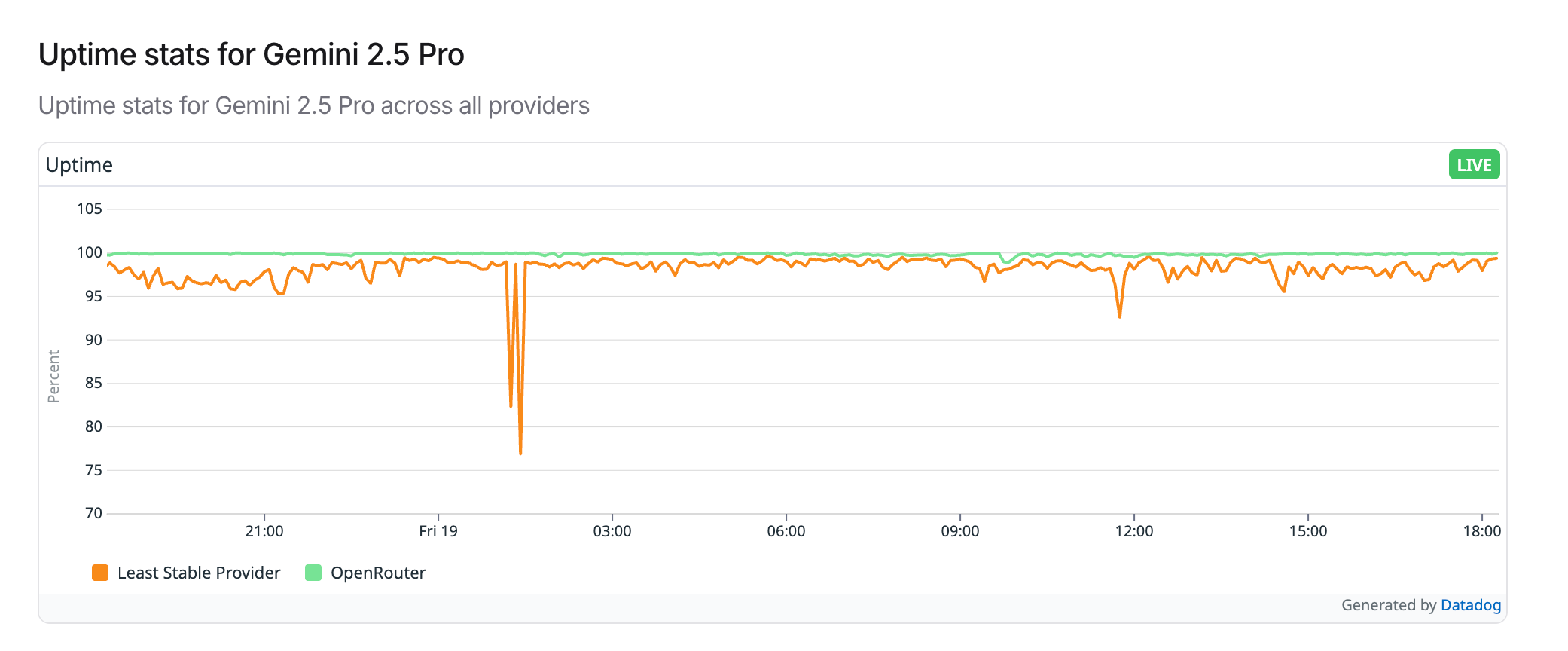 If you've been using coding agents, you'll know how flakey they can be, often getting stuck and requiring retries, a bit like your 56k's modem dropping in bad weather or someone wanting to do a call.
If you've been using coding agents, you'll know how flakey they can be, often getting stuck and requiring retries, a bit like your 56k's modem dropping in bad weather or someone wanting to do a call.
This isn't unsurprising, as much as some commentators believe AI is overhyped, because AI token usage is absolutely exploding. While the 'Big 3' AI companies (Google, Anthropic and OpenAI) don't publish public statistics, OpenRouter does:
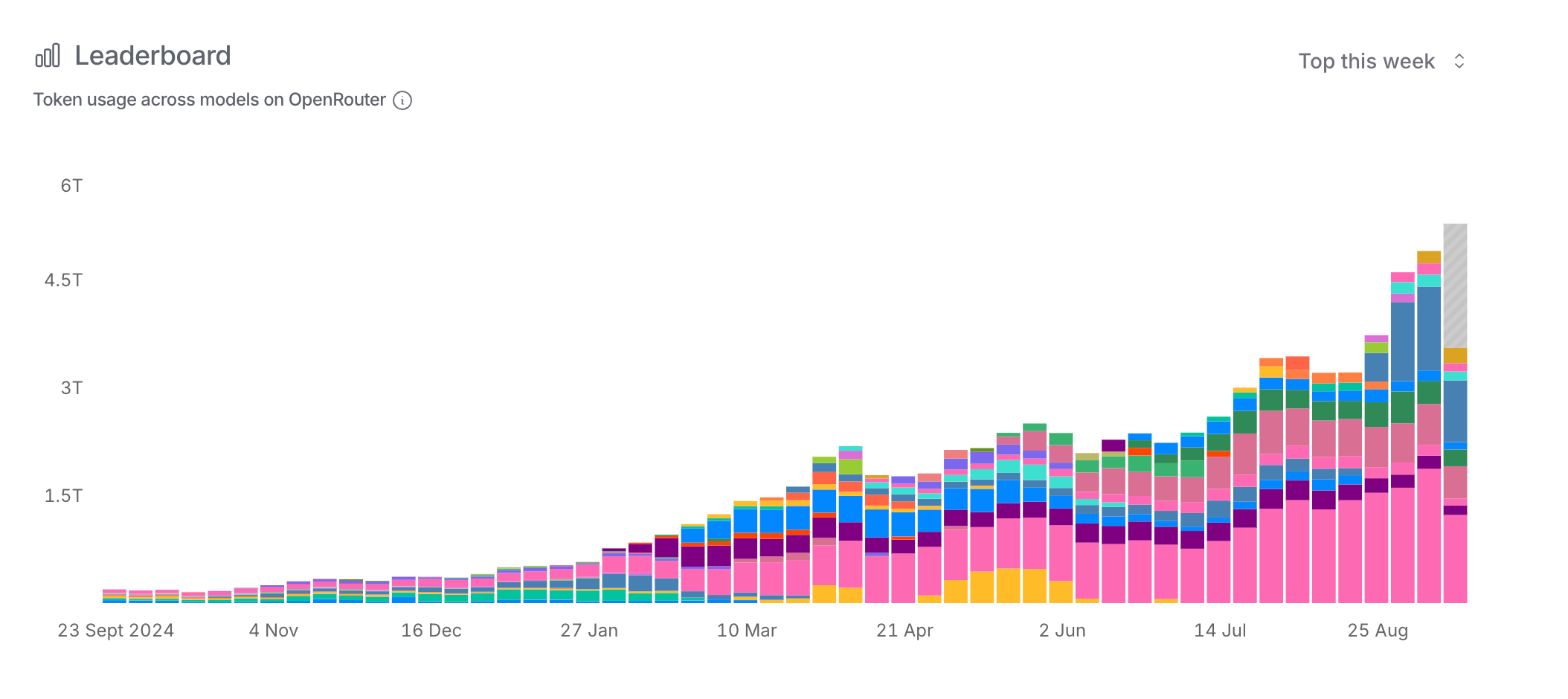 Again, we must caveat this data strongly:
Again, we must caveat this data strongly:
- Firstly, OpenRouter almost certainly routes a tiny proportion of LLM requests vs the global market, meaning these statistics could be distorting trends
- Secondly, Grok (especially) is "dumping" a lot of free LLM tokens on the market getting feedback on their models via OpenRouter, which is probably twisting these statistics
The fact that we're trying to understand a revolutionary shift in software development through the tiny window of OpenRouter's data is telling. Google, Anthropic, and OpenAI guard their usage statistics like state secrets. The only glimpse we get is from OpenRouter, which likely handles <1% of global LLM traffic, yet even this tiny sample shows a 50x increase.
Given that agentic coding workflows consume probably something on the order of 1000x the tokens that non-agentic 'chats' or most API calls do, so it is not surprising to see such a big increase.
This is no doubt putting absolutely enormous strain on the infrastructure behind the scenes, which reminds me a lot of the first days of broadband when the ISPs really struggled to handle peak time loads on their interconnects.
Tok/s is all we need?
More interestingly is the speed at which LLMs operate. Right now frontier models tend to crawl along at 30-60tok/s, which for me at least when I'm operating Claude Code in fully supervised mode is slow enough to get frustrating.
I haven't had success trying to run multiple Claude Code instances at once - the context switching involved becomes too intense past two instances, for me at least. The workflow I've managed to get onboard with is having one agent in plan mode planning the next task, while I work on one in supervised mode, but even this has drawbacks as it gets out of date with the changes.
I've been playing around with Cerebras Code which (was) a fork of Gemini CLI produces tokens 20-50x faster (very similar to the leap from dialup to the first ADSL/cable modems in speed increase).
At 2000tok/s suddenly the bottleneck very quickly becomes you. It becomes very tempting to just start accepting everything, because it comes in so fast, which leads to terrible results. Gemini CLI currently still feels very far behind Claude Code, especially in context management, so it wasn't quite the leap forward I was hoping for, but did give me a glimpse of the future.
However, it did get me thinking to what huge amounts of tok/s would allow, but first let me explain how I think about the milestones in LLMs for software engineering.
Where we are on the coding agent journey
My journey with LLMs for software development in a professional sense has had 3 main phases so far:
- GPT3.5 era: asking the odd question, and usually getting a very hallucinated answer on anything non-trivial. Where we are now felt very very far away when we were here.
- GPT4/Sonnet 3.5 era: the quality of the responses improved so much that it became an essential assistant to ask questions and write small snippets of code. I never seemed to gel with in IDE assistants, so it was a lot of copying and pasting between the IDE and the chat UI
- Supervised CLI Agents: we're here now, where most of my development work is assisted by a coding agent, with me supervising all output.
I think the next era, which I think may be enabled very soon by much higher tok/s infrastructure, is a more unsupervised approach where perhaps 5-10 attempts are made in parallel at a task by the agent. Some (semi?) automated evaluation happens and you get presented with the 'best one' and then iterate from there.
This does match my experience with running agents in unsupervised mode, sometimes it gets it, but mostly it doesn't and it's better to start from scratch. Running in supervised mode allows you to stop this diverging.
You may ask why we can't just do this with slower models - and while we definitely can, I think for developer experience waiting 1-10 minutes for a bunch of options breaks the development cycle too much. If we were running at 2000tok/s we could basically get an order of magnitude more complicated tasks done in a similar workflow speed as we have now.
Infinite demand loop
We're trapped in a potentially infinite demand loop that makes traditional infrastructure scaling look quaint. Every time we improve the LLM models, we don't just use it more efficiently - we fundamentally change how we work in ways that consume an order of magnitude more resources.
A lot of the discourse in the press is expecting something similar to what happened in the early 2000s telecoms crash - where capacity was built out far faster than consumption (and in recent years, broadband bandwidth consumption has virtually plateaued - growing only 10-15% y/y in many markets). While I'm not ruling out some pullback in datacentre construction, I don't see the fundamental demand curve flatlining in the same way.
This is, however, where my ISP analogy breaks down. The speed of semiconductor process improvements has really stalled over the past years (unlike networking capacity which has grown far faster than demand). This then leads to limited efficiency improvements - and is setting a 'cap' on how much supply can be delivered.
Charging models
I think this will then result in less advantageous pricing models for developers, which are very 'unrefined'. While I don't think inference is a huge loss leader; there are clearly huge challenges for the providers at 'peak times'. These tend to be when both the US market and Europe market overlap in work hours.
There must be enormous spare capacity outside these hours, and I think we'll see 'off peak' plans allowing far more consumption outside the peak windows. While OpenAI and Anthropic offer reduced rates for batch processing, this isn't quite the same thing as it's not suitable for interactive agentic workflows. I also suspect we'll see other pricing model "innovation" to try and flatten the demand across the day.
The bottom line
Each of these 'phases' of LLM growth is unlocking a lot more developer productivity, for teams and developers that know how to harness it. I think there is a lot of change coming to how software engineers work and a lot of developers and teams are not prepared for it.
My recommendation is to really keep up to date with the all the developments and try and be as curious as possible - I learnt this the hard way by totally discounting Claude Code as a dead end until I tried it properly for a few hours and realised how powerful it was compared to a lot of the other approaches I'd seen.
I don't think we're in a transition period heading towards stability any time soon and it feels like there is still so much low hanging fruit to improve agents on a tooling level, never mind what would be possible with much faster models.
In my experience the developers that can harness this change the best are the more experienced ones. However, paradoxically in my experience these are often the ones that dismiss it the most.