Is the AI Compute Crunch Here?
In January I wrote about the coming AI compute crunch. Two months later, I think "coming" was the wrong word.
We're starting to see serious signs that some providers are really struggling to meet demand. I still think this is a seriously underpriced risk which has major implications for how much adoption AI can have over the next year or two.
Supply is struggling to keep up with demand
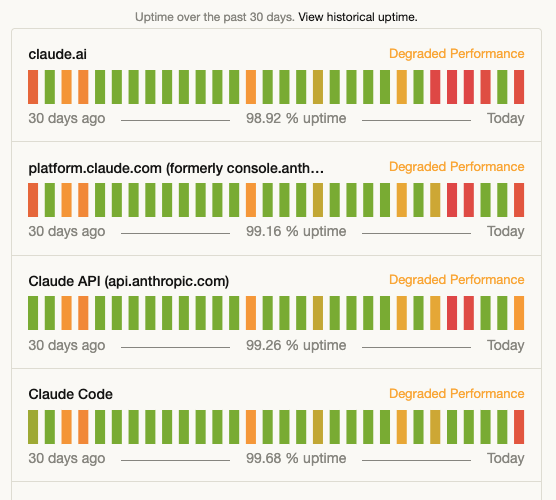
Anthropic's uptime last week was not good, to say the least. Down to the "one 9" at one point. While they've always had some issues (and IME all the major frontier labs are extremely generous with downtime calculations), it was extremely poor last week.
Interestingly though, some of Anthropic's staff started tweeting that it was down to unprecedented growth - that was "genuinely hard to forecast".
I think for the first time I can recall, they are actively degrading their product(s) - by their own admission - to attempt to free up enough compute.
Some of the measures they took included reducing the default effort to medium on Opus 4.6, temporarily removing access to the older Opus 4, 4.1 and Sonnet 4.5 models from Claude Code and disabling prompt suggestions.
Now this isn't the end of the world, but given Claude Code is such a high profile and successful product for Anthropic, I'm sure they definitely would not have wanted to take any corrective action like this if they had any alternative.
It's fair to question whether this is just a one time problem caused by a big spike in people migrating from ChatGPT to Claude. But if you've used eg OpenRouter you'll know how painful the reliability is over the entire industry.
Alibaba Cloud's CEO back in November said “We’re not even able to keep pace with the growth in customer demand, in terms of the pace at which we can deploy new servers”. 4 months later, the situation is as dire as it was back then:
 > Alibaba Cloud uptime on OpenRouter, showing 6tps median output token/s on their flagship Qwen3.5 397B A17B model, suggesting extreme contention for inference resource still
> Alibaba Cloud uptime on OpenRouter, showing 6tps median output token/s on their flagship Qwen3.5 397B A17B model, suggesting extreme contention for inference resource still
It's worth noting that Alibaba Cloud International is headquartered in Singapore, not mainland China, and serves global customers - so the export controls narrative is not as straightforward as it might seem. Regardless, I think it's fair to say that the "AI bubble" narrative of tens/hundreds of billions of dollars of compute needlessly sitting idle is not widespread.
The agentic inflection point
As I wrote back in November, it feels like we passed a significant milestone in the autumn of 2025 in terms of model capabilities. If anything, this has accelerated significantly with Opus 4.6 and (now) GPT 5.4, both of which I've found incredible at SWE tasks (and importantly, other "professional service" tasks).
Given there seems to be no scaling wall currently, at least for "STEM" tasks, more and more complex processes - from building C compilers to hard mathematic/algorithmic problems are likely to be well suited for agentic models. This therefore causes more and more demand for tokens - and agentic processes absolutely eat tokens compared to other uses of LLMs.
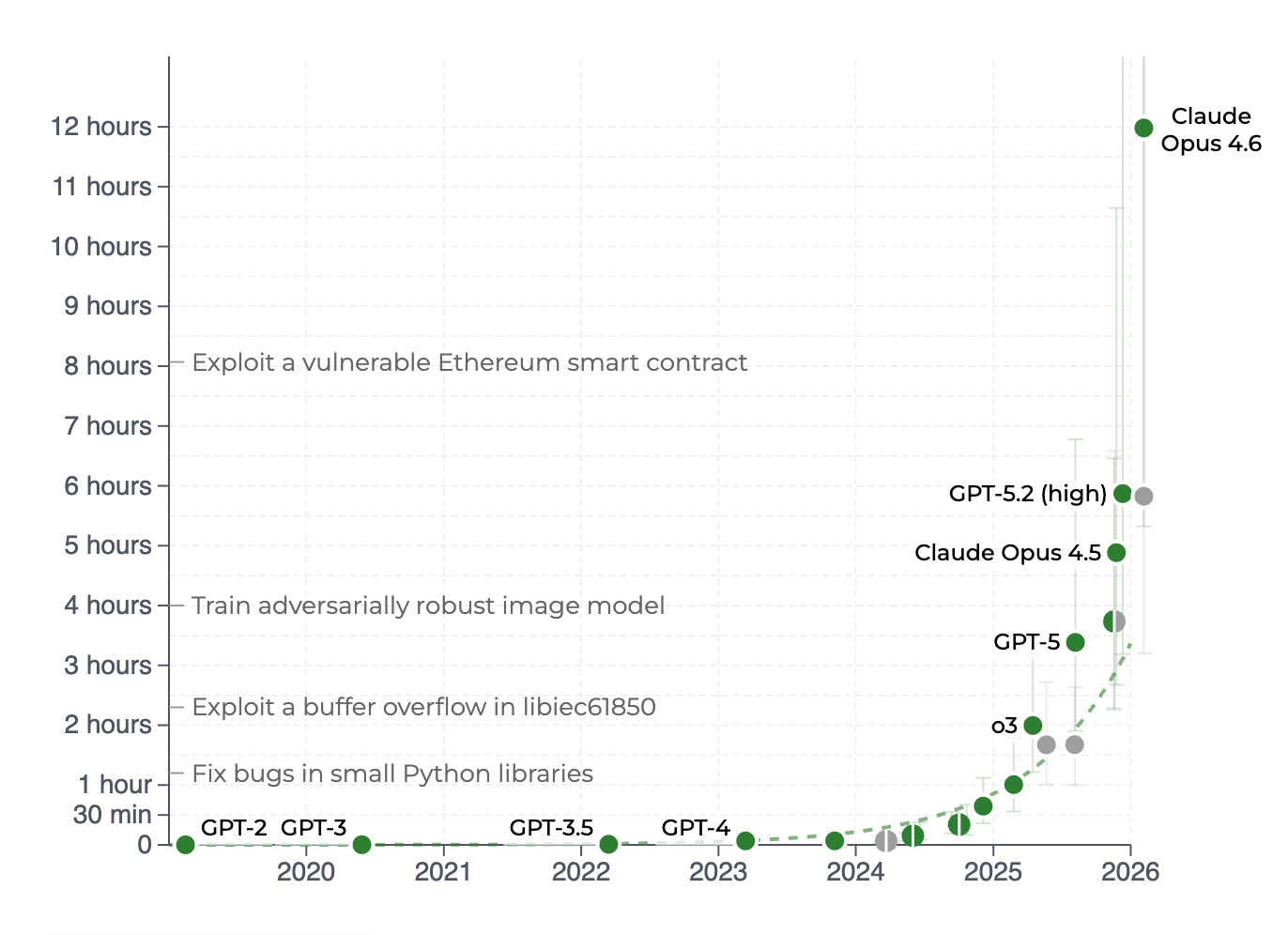 Running some napkin maths on this shows still how early this is.
Running some napkin maths on this shows still how early this is.
Anthropic published in their Series G announcement that Claude Code is doing $2.5b of annual run rate revenue.
If we go off a midpoint of their public pricing, that works out to $200m/month of Claude Code/Cowork revenue - which would be 2 million users at $100/month.[1]
Given the available market of professional/managerial workers in the OECD alone is somewhere in the region of 200-300 million people, and globally over 500 million, it's fair to say that agentic AI tool penetration is in the low single digits % of knowledge workers as a whole. Even if you included OpenCode, Cursor and Codex from OpenAI I very much doubt you have much more penetration, given these tools - unlike Claude Code/Cowork - are heavily adopted by software engineers rather than knowledge workers more broadly.
It's also worth noting that enterprise adoption of Cowork is very much still in pilot phase. Most large organisations are trialling it with small teams, not rolling it out company-wide. If even a fraction of those pilots convert to full deployments over the coming year, the demand increase could be enormous.
If we are starting to see so many provider supply issues with 1-2% adoption, it's hard for me to see how the industry is going to cope with much more than 5% of the world's knowledge workers start burning tokens at work with these tools.
As I wrote in the post in January, I believe DRAM supply sets a hard cap of ~15GW of AI infrastructure until 2027. While I won't rewrite the entire article here, this seems extremely tight given the huge adoption curve we are seeing.
Equally, I think many people are misreading AI datacenter delays or cancellations in the press as being due to financing not being available or "cold feet" on behalf of investors or customers. In my eyes, (most) are likely to be slipping significantly because of power, compute, memory and/or (just as importantly) construction labour availability.
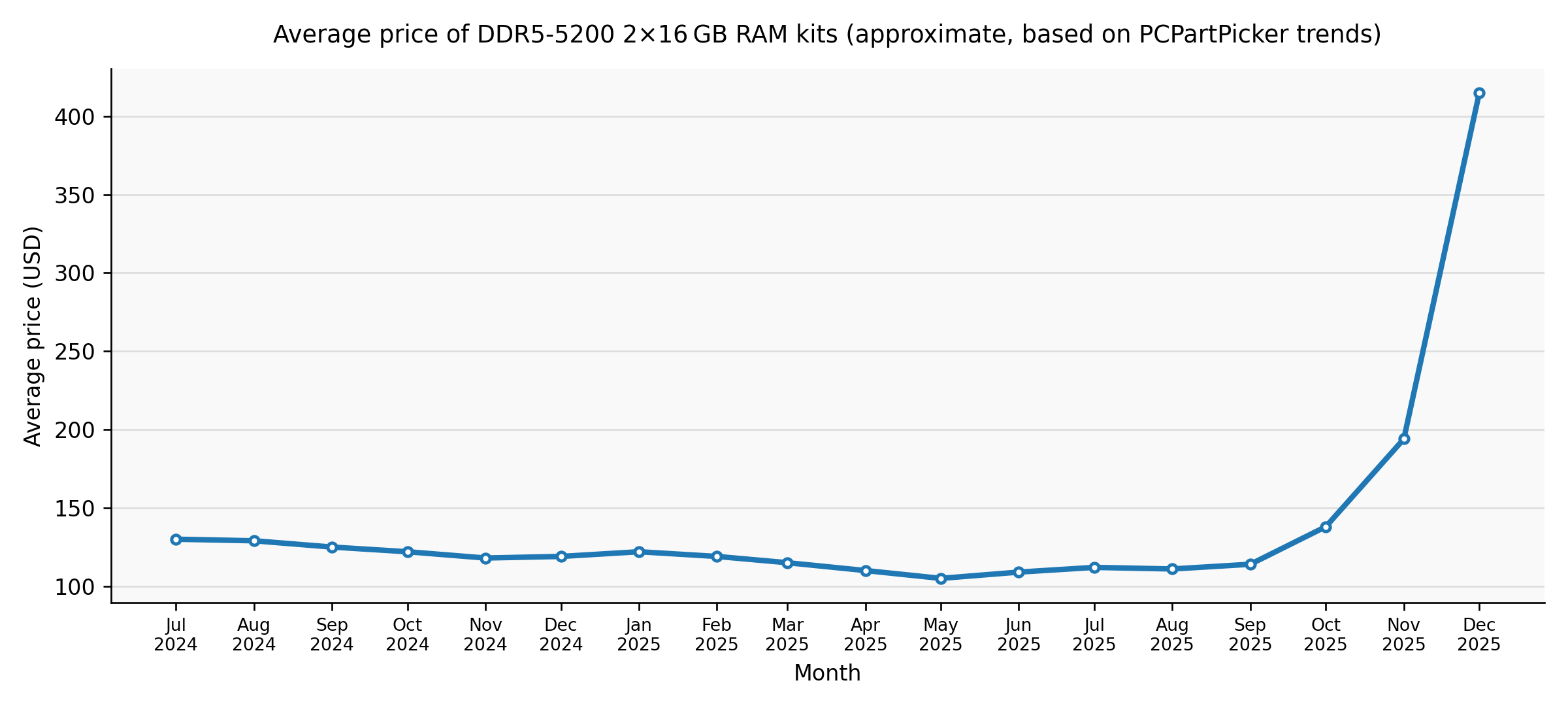
Given DRAM prices continue to rise[2], until this availability improves, no amount of money from Oracle, Softbank or Codeweaves is going to get you an AI datacentre up and running.
What to watch for
I think the recent product changes Anthropic makes are really the canary in the coalmine for inference demand. If I'm directionally correct on this, we're going to see serious inference supply constraints, probably getting increasingly worse over 2026 and 2027 before they get a lot better when new fab capacity starts coming online en masse in 2028.
One thing I really suspect we'll see a lot more of is much more generous rate limits at 'off peak' times - likely to be early morning UTC - as there is no doubt a lot of "idle" compute sitting there[3]. Squeezing the peaks and troughs here will be essential for improving efficiency of their stack.
If you work in a business or enterprise context with AI providers, I'd strongly recommend locking in annual (or longer) contracts if possible - and assume the number of seats you need will increase much more than just your SWE team.
As end users this is far more difficult. The best hedge is not being locked into a single provider. The switching costs between Claude, OpenAI, Gemini and the open weights models are low - use that to your advantage - I've really enjoyed using OpenCode for many tasks that are very easy to switch out providers.
Of course, I could be wrong. Perhaps SRAM-based inference really takes off into the mainstream and/or enormous efficiency gains are realised and tokens per watt goes stratospheric. But given my day to day experience using Claude Code, Codex, OpenCode and OpenRouter I really don't think that is the correct narrative at the moment.
A lot of the commentary about the AI bubble focuses far too much on the financial engineering. I think looking at the hardware engineering behind the scenes is far more telling.
You could get 10 million users if you assumed everyone was on the $20/month plan, or ~1million if everyone was on the $200/month plan. My guess is somewhere in the middle, low single figure digits millions. ↩︎
DDR5 and HBM (High Bandwidth Memory used in AI accelerators) are different products, but they compete for the same upstream wafer capacity. When memory fabs allocate more wafer starts to HBM production, it reduces DDR5 supply and pushes consumer prices up. The DDR5 price spike is therefore a useful proxy for overall DRAM supply tightness, even though HBM itself trades at much higher ASPs on long-term contracts. ↩︎
Though I'm sure it is being hoovered up for RL inference for training, but I strongly suspect they'd prefer to be selling it to customers. I'm also aware they offer discounts for batch inference, but it's extremely poorly suited for agentic workflows. I think we'll see 'double usage limits' overnight, for example. Or the more negative way of looking at it - that you only get half (or less) the use at peak hours, with your "full" limit being available overnight. ↩︎