How I make CI/CD (much) faster and cheaper
One often overlooked element of the software development lifecycle is CI/CD speed, and relatively how easy it is to improve this with better hardware.
Why does it matter?
CI/CD speed really helps developers stay more efficient on their tasks. The two main benefits are:
- Improved developer productivity. There's nothing worse than having to wait for a very long CI/CD pipeline to run for even small changes. It really breaks you out of the flow.
- Quicker deployments. I've seen some CI/CD pipelines that take nearly an hour to test, build and deploy changes. This slows down the pace of change in your product, and can really bite you when you have a production issue that needs hotfixed as quickly as possible. In my experience this then leads to CI/CD checks being skipped to put fires out, which can then cause other regressions.
With AI agents, CI/CD can now take as long to run (if not longer) as doing small/medium sized changes. Amdahl's Law rears its ugly head again in the software development lifecycle.
The hardware is too damn slow
This applies to all CI/CD platforms that I've come across, not just GitHub Actions.
Nearly all organisations I know tend to use the standard GitHub Action Workers. You may use the larger runners even. They are convenient and don't require any operations. However, like many things in the cloud, they are slow.
The default runner GitHub actions runner has 2vCPUs and 7GB of RAM. While 7GB of RAM sounds passable, 2vCPUs is incredibly vague.
A vCPU usually refers to a thread rather than a physical core. With hyperthreading and oversubscription on shared cloud infrastructure, you're typically getting a fraction (~50%) of an already-shared physical core from a server CPU that's optimized for massive multithreading, not single-thread performance. Some EPYC CPUs designed for hyperscalers even use efficiency cores (4c/5c) which are even slower but pack more cores per die - though it doesn't look like these ones are being used here.
Doing some diagnostic checks (these may vary), I was getting consistently EPYC 7763 CPU, which is nearly 5 years old now. It also only supports AVX2 and not AVX512 which can provide a very nice additional speedup for many software engineering tasks.
Let's compare this to the latest Ryzen CPUs at the time of writing on CPU benchmark. Keep in mind we only have one physical core assigned - not 64!
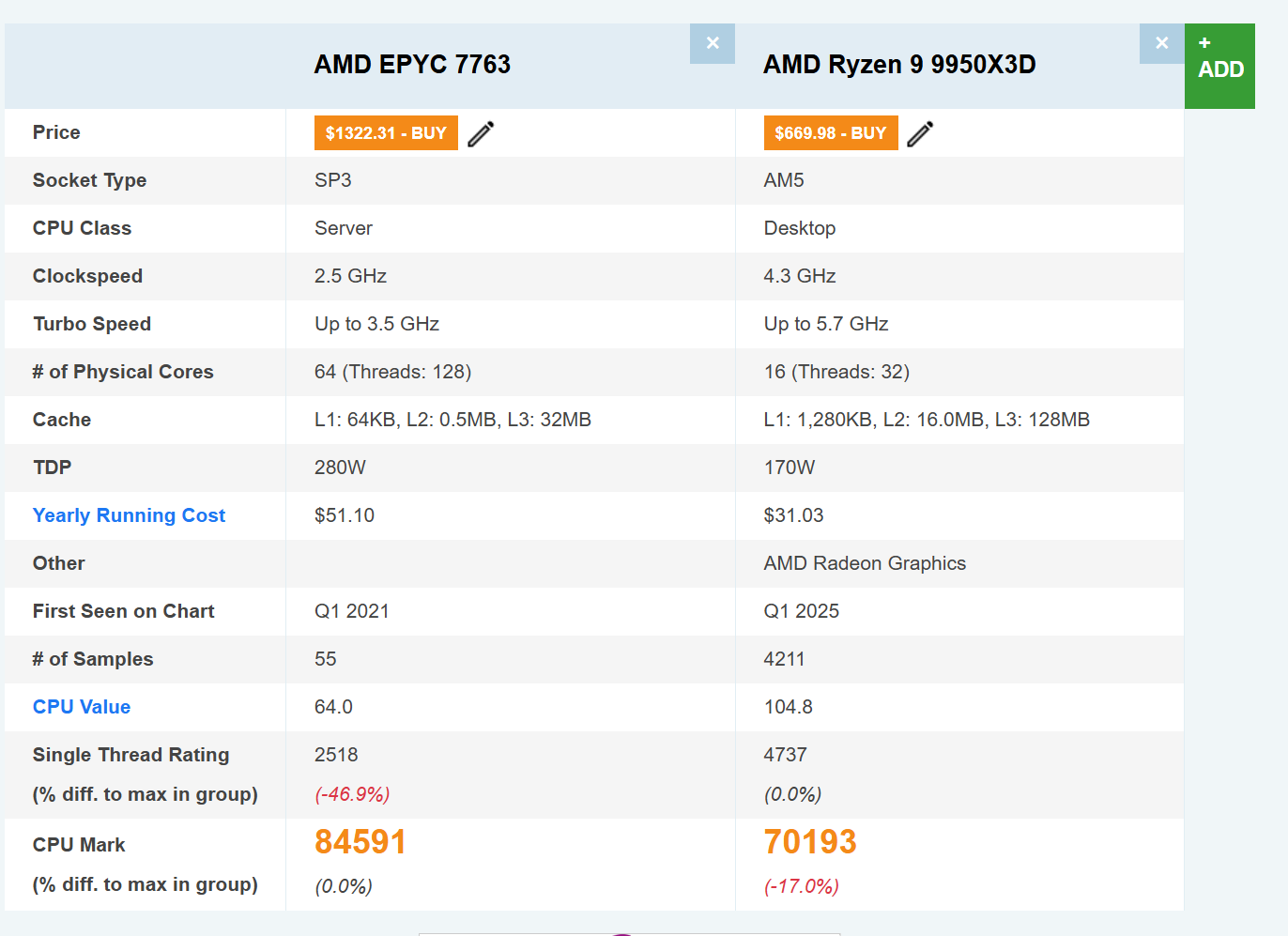
As you can see on single thread performance, the Ryzen 9950X3D is ~twice as fast at single thread performance - and despite only having one quarter of the CPU cores, is nearly as fast as the Epyc chip in multicore.
Let's compare the two side by side:
| GitHub Actions (EPYC 7763) | Ryzen 9950X3D | Comparison | |
|---|---|---|---|
| Release Year | Q1 2021 | Q1 2025 | 4 years newer |
| Cores Available | 1 physical (2 threads) | 16 cores (32 threads) | 16x cores |
| Base/Turbo Clock | 2.5 GHz / 3.5 GHz | 4.3 GHz / 5.7 GHz | 1.7x/1.6x |
| L1d Cache | 32 KiB (1 core) | 512 KiB (16 cores) | 16x total |
| L1i Cache | 32 KiB (1 core) | 512 KiB (16 cores) | 16x total |
| L2 Cache | 512 KiB (1 core) | 16 MiB (16 cores) | 32x total |
| L3 Cache | 32 MiB (shared, 0.5-8MB effective) | 128 MiB (3D V-Cache) | 16-256x effective |
| AVX Support | AVX2 (256-bit) | AVX-512 (512-bit) | 2x wider vectors |
| Memory Speed | DDR4-2666 (likely) | DDR5-5600+ | 2.1x faster |
| Single Thread Rating | 2,518 | 4,737 | 1.88x faster |
| Multi Thread Rating | ~2,000-5,000 (server load) | 70,193 | 14-35x faster |
As you can see, a pretty standard gaming CPU absolutely wipes the floor with the standard cloud hosted runners.
Just on single threaded CPU alone, you will basically double the speed of your pipelines on any serial CPU contended parts just by switching to a bare metal server.
I/O
It gets even worse for the standard runners though. Doing some non-scientific testing (but matches my anecdotal experience), I/O is incredibly slow.
Accessing a 10GB file on disk with dd we get:
- Write: ~200MB/sec
- Read: ~200MB/sec
A fairly affordable PCIe5 NVMe on bare metal will give 6000MB/sec quite easily - 30x faster. Given you probably aren't to worried about data integrity in CI/CD, you could even run them in RAID0 and get 2x the speed 🤯
It gets even worse for general small file access, with very slow IOPS (around 10,000, but varies a lot depending on neighbours), vs 1million+ on a PCIe5 NVMe. This is a real killer for software developers, with npm often installing hundreds of thousands of small files. It also explains the dreadful performance I'm sure you're aware of of apt-get.
Networking
The final problem I see with hosted runners, is that they aren't located near your infrastructure for testing - sometimes you'll have other services your pipelines need to call out to.
I seem to randomly get assigned servers in US Central and US East on GitHub Actions. However, being in the UK, that's 100ms of latency to some of our European operations. This can really add up - and if you are in Asia, Africa, LatAm or Oceania can be a total killer.
It also is a lot easier to lock down just a handful of known static IP ranges for security on these, vs having to either whitelist huge ranges or pay for GitHub Enterprise.
Overall comparison and pricing
I'd recommend getting a bare metal Ryzen server with as much RAM as you can afford. OVH is a good option, so is Hetzner.
For example, Hetzner offers a AMD Ryzen 7950X3D with 128GB of DDR5 and 2TB of PCIe4 NVMe for ~$100/month.
While not quite as fast as the above comparison, it's very close. I suspect if you move your CI/CD workflows to this, you'll find they run 2-10x faster straight away without any configuration changes - all you have to do is secure the box appropriately and setup the GitHub actions self runner, which is very simple to do.
To get roughly comparable hardware from GitHub actions you need to use the 32 core runner, which costs $0.128/min, or $5000+/month for sustained usage! And even then it likely will be (often significantly) slower for many tasks because of the lower single thread performance and IO issues (which AFAIK do not change radically with more cores).
Now, you may not have sustained usage 24/7 on your pipelines, which doesn't make it a particularly fair comparison - but even assuming a 25% usage level, it works out 10x cheaper for significantly more speed.
CI/CD is a perfect use case for bare metal - even if the machine goes offline (which in my experience is much more rare than GitHub itself going down!), its a one line change to your pipelines.yml to go back to GitHub hosted ones.
It's also an absolute no brainer if you are also seeing huge cost increases on your GitHub actions bill because you are running many more PRs and deployments with agentic software engineering.
*NB: There are SaaS providers offering this kind of setup, but the pricing is nowhere near competitive with bare metal, and in my experience the management of these is so trivial it's much better to just get a bare metal box or ten and set it up yourself. You can also get the very fastest hardware easily and choose a provider that is geographically close to you.