Are OpenAI and Anthropic Really Losing Money on Inference?
I keep hearing what a cash incinerator AI is, especially around inference. While it seems reasonable on the surface, I've often been wary of these kind of claims, so I decided to do some digging.
I haven't seen anyone really try to deconstruct the costs in running inference at scale and the economics really interest me.
This is really napkin math. I don't have any experience at running frontier models at scale, but I do know a lot about the costs and economics of running very high throughput services on the cloud and, also, some of the absolutely crazy margins involved from the hyperscalers vs bare metal. Corrections are most welcome.
Some assumptions
I'm only going to look at raw compute costs. This is obviously a complete oversimplification, but given how useful the current models are - even assuming no improvements - I want to stress test the idea that everyone is losing so much money on inference that it is completely unsustainable.
I've taken the cost of a single H100 at $2/hour. This is actually more than the current retail rental on demand price, and I (hope) the large AI firms are able to get these for a fraction of this price.
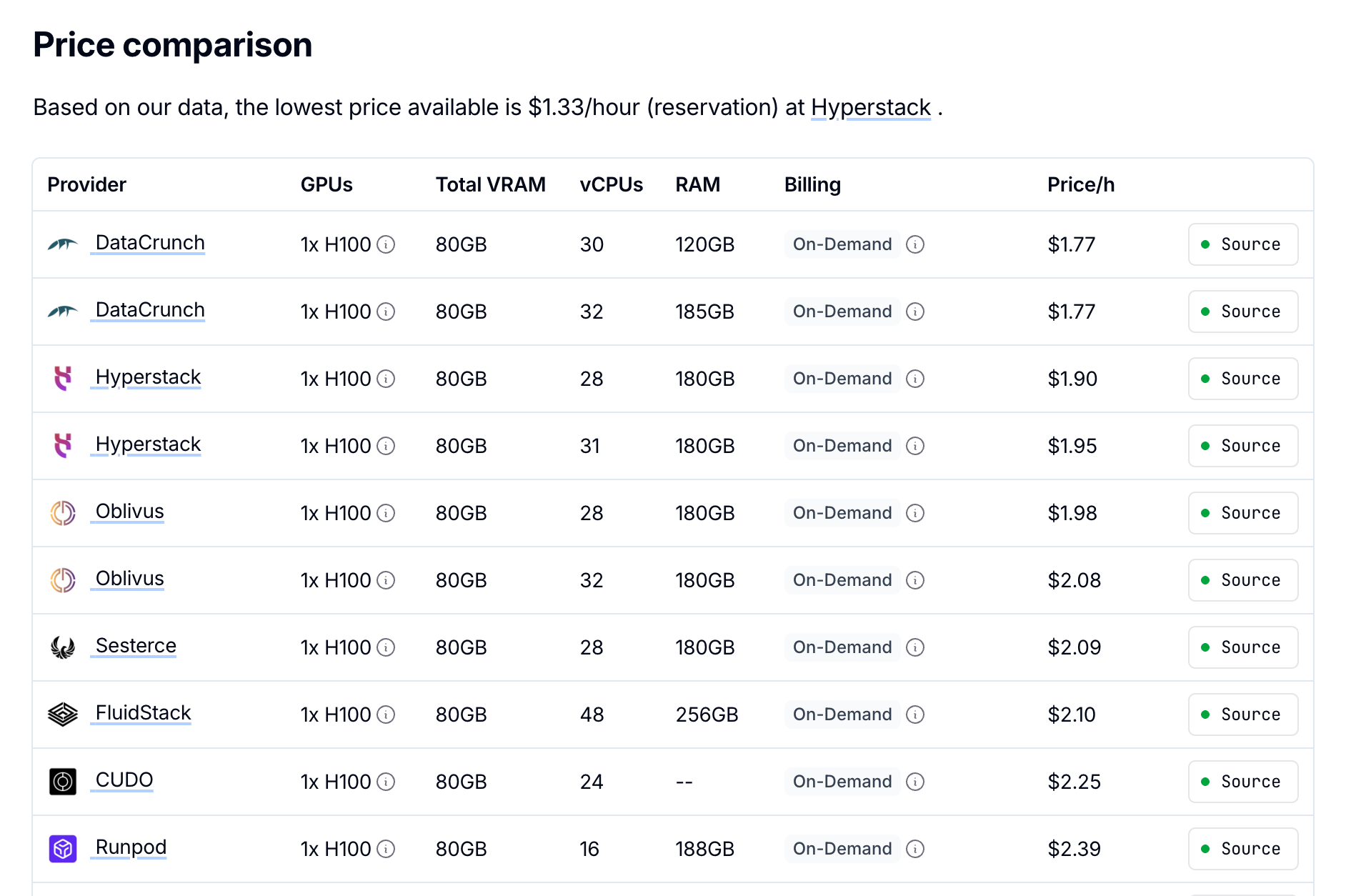
Secondly, I'm going to use the architecture of DeepSeek R1 as the baseline, 671B total params with 37B active via mixture of experts. Given this gets somewhat similar performance to Claude Sonnet 4 and GPT5 I think it's a fair assumption to make.
Working Backwards: H100 Math From First Principles
Production Setup
Let's start with a realistic production setup. I'm assuming a cluster of 72 H100s at $2/hour each, giving us $144/hour in total costs.
For production latency requirements, I'm using a batch size of 32 concurrent requests per model instance, which is more realistic than the massive batches you might see in benchmarks. With tensor parallelism across 8 GPUs per model instance, we can run 9 model instances simultaneously across our 72 GPUs.
Prefill Phase (Input Processing)
The H100 has about 3.35TB/s of HBM bandwidth per GPU, which becomes our limiting factor for most workloads. With 37B active parameters requiring 74GB in FP16 precision, we can push through approximately 3,350GB/s ÷ 74GB = 45 forward passes per second per instance.
Here's the key insight: each forward pass processes ALL tokens in ALL sequences simultaneously. With our batch of 32 sequences averaging 1,000 tokens each, that's 32,000 tokens processed per forward pass. This means each instance can handle 45 passes/s × 32k tokens = 1.44 million input tokens per second. Across our 9 instances, we're looking at 13 million input tokens per second, or 46.8 billion input tokens per hour.
In reality, with MoE you might need to load different expert combinations for different tokens in your batch, potentially reducing throughput by 2-3x if tokens route to diverse experts. However, in practice, routing patterns often show clustering around popular experts, and modern implementations use techniques like expert parallelism and capacity factors to maintain efficiency, so the actual impact is likely closer to a 30-50% reduction rather than worst-case scenarios.
Decode Phase (Output Generation)
Output generation tells a completely different story. Here we're generating tokens sequentially - one token per sequence per forward pass. So our 45 forward passes per second only produce 45 × 32 = 1,440 output tokens per second per instance. Across 9 instances, that's 12,960 output tokens per second, or 46.7 million output tokens per hour.
Raw Cost Per Token
The asymmetry is stark: $144 ÷ 46,800M = $0.003 per million input tokens versus $144 ÷ 46.7M = $3.08 per million output tokens. That's a thousand-fold difference!
When Compute Becomes the Bottleneck
Our calculations assume memory bandwidth is the limiting factor, which holds true for typical workloads. But compute becomes the bottleneck in certain scenarios. With long context sequences, attention computation scales quadratically with sequence length. Very large batch sizes with more parallel attention heads can also shift you to being compute bound.
Once you hit 128k+ context lengths, the attention matrix becomes massive and you shift from memory-bound to compute-bound operation. This can increase costs by 2-10x for very long contexts.
This explains some interesting product decisions. Claude Code artificially limits context to 200k tokens - not just for performance, but to keep inference in the cheap memory-bound regime and avoid expensive compute-bound long-context scenarios. This is also why providers charge extra for 200k+ context windows - the economics fundamentally change.
Real-World User Economics
So to summarise, I suspect the following is the case based on trying to reverse engineer the costs (and again, keep in mind this is retail rental prices for H100s):
- Input processing is essentially free (~$0.001 per million tokens)
- Output generation has real costs (~$3 per million tokens)
These costs map to what DeepInfra charges for R1 hosting, with the exception there is a much higher markup on input tokens.
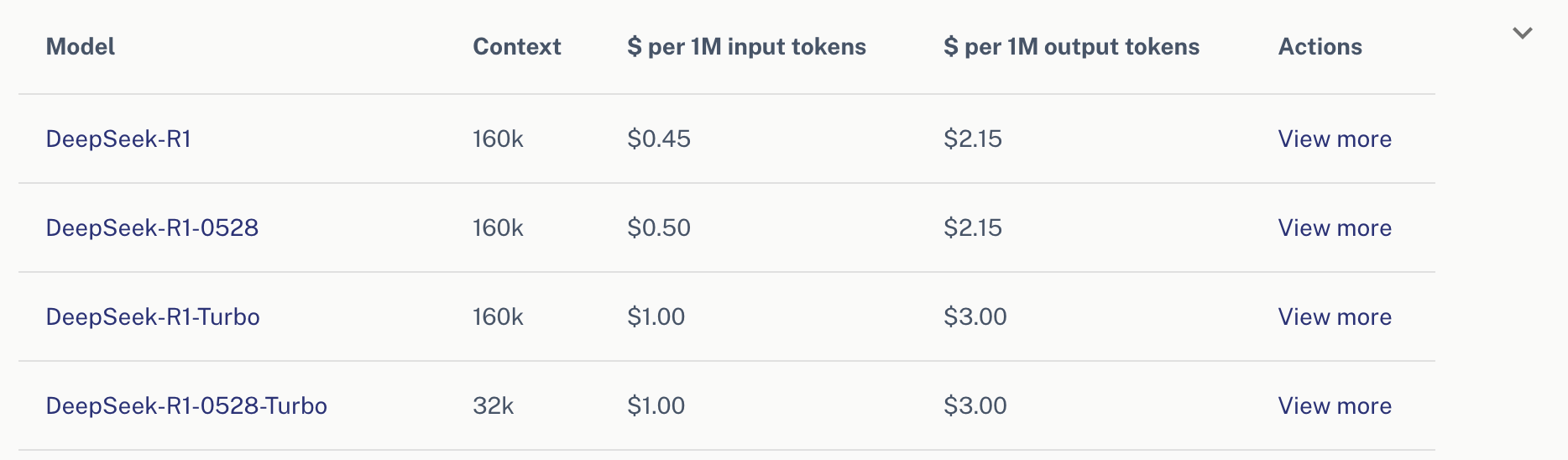
A. Consumer Plans
- $20/month ChatGPT Pro user: Heavy daily usage but token-limited
- 100k toks/day
- Assuming 70% input/30% output: actual cost ~$3/month
- 5-6x markup for OpenAI
This is your typical power user who's using the model daily for writing, coding, and general queries. The economics here are solid.
B. Developer Usage
- Claude Code Max 5 user ($100/month): 2 hours/day heavy coding
- ~2M input tokens, ~30k output tokens/day
- Heavy input token usage (cheap parallel processing) + minimal output
- Actual cost: ~$4.92/month → 20.3x markup
- Claude Code Max 10 user ($200/month): 6 hours/day very heavy usage
- ~10M input tokens, ~100k output tokens/day
- Huge number of input tokens but relatively few generated tokens
- Actual cost: ~$16.89/month → 11.8x markup
The developer use case is where the economics really shine. Coding agents like Claude Code naturally have a hugely asymmetric usage pattern - they input entire codebases, documentation, stack traces, multiple files, and extensive context (cheap input tokens) but only need relatively small outputs like code snippets or explanations. This plays perfectly into the cost structure where input is nearly free but output is expensive.
C. API Profit Margins
- Current API pricing: $3/15 per million tokens vs ~$0.01/3 actual costs
- Margins: 80-95%+ gross margins
The API business is essentially a money printer. The gross margins here are software-like, not infrastructure-like.
Conclusion
We've made a lot of assumptions in this analysis, and some probably aren't right. But even if you assume we're off by a factor of 3, the economics still look highly profitable. The raw compute costs, even at retail H100 pricing, suggest that AI inference isn't the unsustainable money pit that many claim it to be.
The key insight that most people miss is just how dramatically cheaper input processing is compared to output generation. We're talking about a thousand-fold cost difference - input tokens at roughly $0.005 per million versus output tokens at $3+ per million.
This cost asymmetry explains why certain use cases are incredibly profitable while others might struggle. Heavy readers - applications that consume massive amounts of context but generate minimal output - operate in an almost free tier for compute costs. Conversational agents, coding assistants processing entire codebases, document analysis tools, and research applications all benefit enormously from this dynamic.
Video generation represents the complete opposite extreme of this cost structure. A video model might take a simple text prompt as input - maybe 50 tokens - but needs to generate millions of tokens representing each frame. The economics become brutal when you're generating massive outputs from minimal inputs, which explains why video generation remains so expensive and why these services either charge premium prices or limit usage heavily.
The "AI is unsustainably expensive" narrative may be serving incumbent interests more than reflecting economic reality. When established players emphasize massive costs and technical complexity, it discourages competition and investment in alternatives. But if our calculations are even remotely accurate, especially for input-heavy workloads, the barriers to profitable AI inference may be much lower than commonly believed.
Let's not hype the costs up so much that people overlook the raw economics. I feel everyone fell for this a decade or two ago with cloud computing costs from the hyperscalers and allowed them to become money printers. If we're not careful we'll end up with the same on AI inference.