A brief history of KV cache compression developments
While much is focused on the improvement of models, there's been radical improvements in the efficiency of KV cache compression. I was curious to figure out just how big the improvements are and why I think it matters so much.
The headline figure: the memory needed to store one token of context has fallen by roughly 100x since 2017. Over the same period, the memory on a top of the range datacentre GPU has gone from 16GB to 288GB - an 18x improvement. The memory wall in AI has mostly been solved with maths, not silicon.
What is a KV cache?
When you use an LLM - either via the web on ChatGPT et al, or agentically via Claude Code, your "context" is stored in a KV cache. This is/has been an incredibly memory intensive process which has led to hard limits on the session length.
Put simply, the longer your "conversation" grows with the LLM, the more KV cache you need. A more efficient KV cache allows you to input more stuff - conversations, code, reference documents, images - in the same amount of memory.
An inexact analogy is compression for audio visual files. It was the MP3 algorithm that allowed audio files in the late 90s to be compressed enough that Napster was (nearly) workable. Equally, MPEG2 allowed digital TV to work, and subsequent algorithms like H.264 allowed Netflix to work well on slow(er) broadband connections.
Without modern video compression codecs, a 4K stream on Netflix would require (many) gigabits of bandwidth to work. With compression codecs, it can be squeezed into a 15mbit/sec bandwidth allocation - a 100x+ compression ratio.
By allowing this efficiency you can often leapfrog hardware improvements. No doubt broadband connections will converge fast enough at some point to allow uncompressed 4K video streams, but compression allows you to roll out improvements far faster, to a wider market.
The inception of KV caches
When transformers first came around in ~2017, a 128K token context window (roughly 100,000 English words) would require ~340GB of GPU memory for one conversation, using MHA. That assumes a 70B-class dense model at 16 bit precision - which works out at about 2.6MB of memory for every single token in your conversation.
In 2017 the absolute state of the art datacentre GPU parts like the Tesla V100 shipped with 16GB of HBM2 memory. So, on that architecture, you'd need ~20 top of the range GPUs to hold one conversation - which these days would feel limiting.
While this is revisionist - you wouldn't be able to have any conversation with a transformer at that point - it shows just how far out hardware and efficiency was.
The first major leap was MQA in 2019, from Noam Shazeer at Google. This allowed a huge 64x reduction (on a model with 64 attention heads) by sharing a single KV head across all query heads. However, this had major downsides - quality took a real hit and training became less stable - and long recall significantly degraded. It saw some adoption (PaLM and Falcon used it), but it was clear the compression was too aggressive.
GQA
As LLMs started ramping up in capability, the context window became an enormous problem. GPT3.5 had a context window limit of just 4K tokens - barely enough to input a few pages of documents. This is no doubt because of the enormous memory requirements.
It's hard to overstate how big a limitation this was. While the models were still at a very early stage, if there weren't further developments in context window efficiency LLMs would have been limited to very short question and answer sessions. Agentic workflows of any type, regardless of model quality, would have been extremely constrained - even defining the tools an agent has access to now requires 20k tokens in Claude Code, before anything is input or output.
The core way LLM providers patched over this was just deleting messages from your session. ChatGPT might just take your first message, and the last n messages that fit in the context window. This led to hilariously bad results, as it'd instantly forget something it had just said a few messages ago. It would have been completely unworkable for any serious document work.
GQA arrived in 2023, allowing groups of query heads to share KV heads - a middle ground between MHA and MQA. With 8 KV head groups this allowed an 8x reduction - with very little quality loss as the session grew. Llama 2 70B and Mistral adopted it almost immediately, and it quickly became the default for open models.
Around the same time another trick emerged in parallel: sliding window attention, where some layers only attend to a fixed window of recent tokens, so their share of the KV cache stops growing entirely. Mistral shipped it in 2023, and Google's Gemma models later interleaved local and global attention layers to similar effect.
Once approaches like this became commonplace, we start seeing a rapid increase in the context window length - no doubt alongside more memory being available. GPT3.5-Turbo allowed 16k context windows, and while the original GPT4 launched at just 8k (with a pricey 32k variant), GPT4-Turbo expanded dramatically to 128k by late 2023.
MLA - the DeepSeek surprise
The next big jump came from DeepSeek in 2024 with MLA. Instead of sharing KV heads between query heads, MLA compresses the keys and values down into a much smaller latent vector, and folds the decompression step into the surrounding projection matrices so the full keys and values never have to be materialised at all. DeepSeek claimed a 93% reduction in KV cache size in their V2 paper - while improving on quality benchmarks, not just holding steady.
This was an important proof point. MQA showed you could compress hard if you accepted the quality hit, and GQA showed a modest compression with almost no hit - but MLA showed you could go an order of magnitude beyond GQA without giving anything up. It's also a decent chunk of how DeepSeek served their models so cheaply that they wiped nearly $600bn off Nvidia's market cap in a single day in early 2025.
Alongside this, quantisation of the KV cache itself - storing the keys and values at 8 or even 4 bit precision rather than 16 - became increasingly standard, roughly doubling or quadrupling effective capacity again on top of everything else. More recent approaches like Google's TurboQuant push this much further still.
(There's also a whole parallel universe of serving-side improvements like vLLM's PagedAttention - but that's about managing KV memory rather than compressing it, so I'm leaving it out of scope here.)
Agentic capabilities
Between late 2023 and 2025 models got somewhat "stuck" in context window size, with OpenAI and Anthropic offering models around the 128-200k token length. It's fair to say that these context lengths were not terrible - they allowed coding tasks and moderately sophisticated document processing. But as true coding agents ramped up, it did become extremely limiting.
In this timespan you had to spend a lot of time thinking about this if you were building or using agents. Reading too many large files would blow through the window, causing the dreaded "compaction" to run - a fairly crude process of trying to summarise everything the agent had access to.
The next major breakthroughs around 2025 were linear-attention hybrids - models like Qwen3-Next and Kimi Linear replaced most of their full attention layers with linear attention, which keeps a small fixed size state per layer rather than an ever-growing cache. Only a minority of layers keep a full KV cache. This (and no doubt other, less publicly known about) approaches allowed context windows to grow to 1M tokens with minimal quality loss. It's presumably a big part of why Anthropic could ship a 1M context window earlier this year without even charging extra for it.
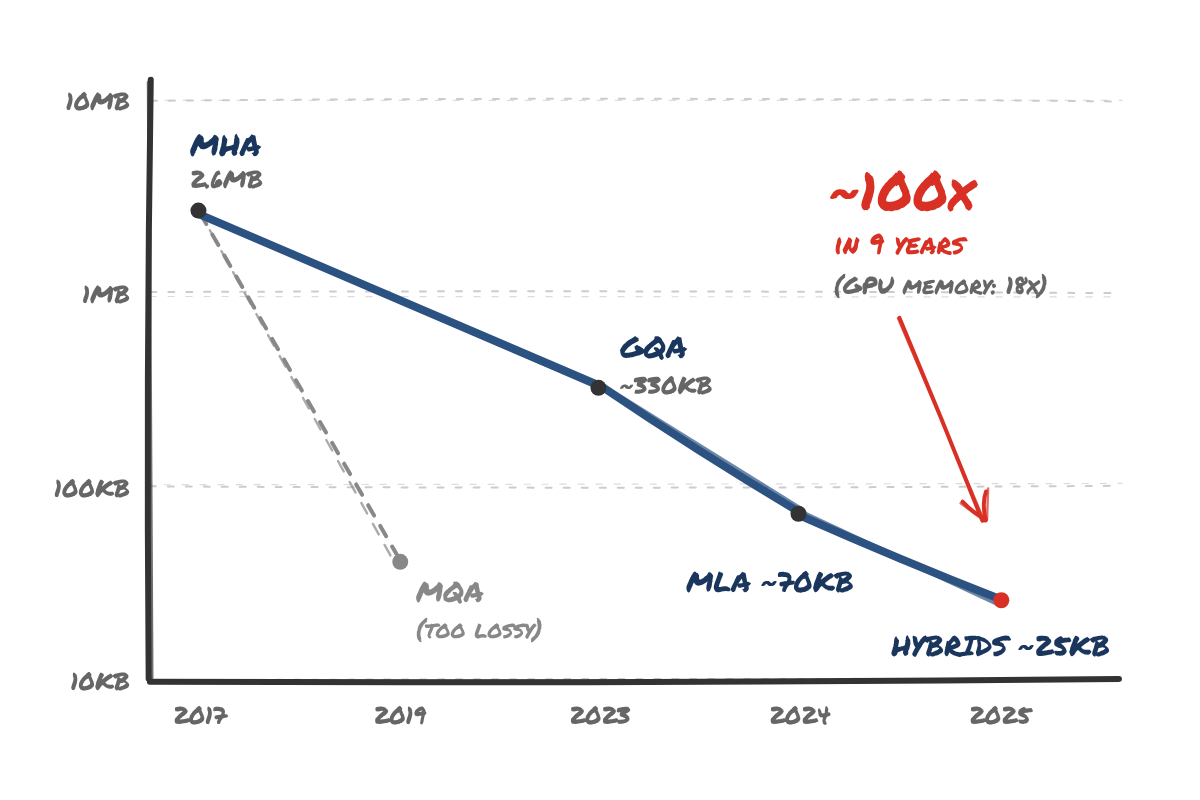
KV cache memory per token of context, on a log scale. GPU memory only improved ~18x in the same period.
The future
There's no sign of this slowing down. Research is increasingly pointed at getting rid of the quadratic attention bottleneck entirely - pure linear and recurrent approaches that keep a fixed size state no matter how long the context grows. Whether they can fully match attention on quality is still an open question, but the hybrids have already shown you don't need every layer to pay full price.
The thing I find most interesting though: across nine years of ~100x compression gains, surprisingly little of it showed up as cheaper. Token prices have come down, sure - but most of the efficiency got spent on longer context windows instead. 4K became 128K became 1M. Much like video codecs got spent on higher resolutions rather than smaller files, we keep spending memory efficiency on more capable agents. And with memory now one of the hardest constraints on the AI buildout, I'd expect that to continue.
As ever in this space, half of this post will probably be out of date within a year. There's an enormous amount of money pointed at making context cheaper - I certainly wouldn't bet against another 100x.